
Learning to play Blackjack with RL
Exploring Blackjack policies with Reinforcement Learning
I’m currently taking a Reinforcement Learning class as part of my Master’s in AI. We’ve been digging into Monte Carlo methods, off-policy learning, and Temporal-Difference updates. It’s fascinating in theory, but I really wanted to see how these methods actually behave in practice.
So I came up with a small side project: train different RL methods on Blackjack, see how they learn to play, and compare them both to each other and to the classic basic Blackjack strategy.

Why Blackjack?
Blackjack is a perfect playground for this kind of experiment.
- I like the game, it’s simple and fun.
- The state space is small and finite, so you can keep it fully tabular.
- It’s simple enough that you don’t need deep networks or tons of compute.
- It’s still interesting: there’s risk, uncertainty, and tricky decisions.
- And there’s a known optimal strategy (the basic strategy) so you can see how well your agent really does.
Choosen Methods
To really see how different reinforcement learning strategies behave, I picked four well-known methods that highlight different ideas about how agents can learn.
1. On-Policy Monte Carlo (ε-greedy)
This method sticks to learning from its own behavior. The agent plays using the same policy it wants to improve, following an ε-greedy approach. That means it mostly chooses what it thinks is the best action but still explores occasionally to make sure it covers the state space well. It waits until the end of each game to update its value estimates, so it has to rely on full episodes to learn.
This method is simple and stable for small problems like Blackjack but can need a lot of episodes to really see every possible situation.
2. Off-Policy Monte Carlo with Ordinary Importance Sampling
Here, the agent generates episodes using a separate behavior policy, usually fully random. The goal is to learn about a different, better target policy that’s more optimal. To adjust for the mismatch between the behavior policy and the target policy, it uses importance sampling ratios to reweight the returns.
This gives you a lot of flexibility to reuse any data you collect, but the downside is that it can have very high variance if many episodes don’t match the target policy well.
3. Off-Policy Monte Carlo with Weighted Importance Sampling
This approach works the same way as ordinary importance sampling but adds a normalization step to reduce variance. The agent still collects data using the behavior policy and wants to learn about a better target policy, but it scales the updates so that extreme weights don’t dominate the results.
This makes off-policy learning more practical and stable, though it can still be less efficient than on-policy methods when direct sampling is easy.
4. Q-Learning (Off-Policy TD Control)
Q-Learning takes a different route by using temporal-difference updates instead of waiting for the entire game to finish. It updates its Q-values step by step while it plays, using the estimated value of the next state’s best action to bootstrap each update. The agent still explores with an ε-greedy behavior but learns about the best possible greedy policy in the background.
This makes Q-Learning stable and scalable, especially for bigger or continuous state spaces, though it needs careful tuning of the learning rate and exploration to get good results.
The Experiment
Each agent was trained for 100,000 episodes in the same Blackjack environment with the same state representation. After training, I tested each learned policy on 50,000 new hands, playing purely greedy to see the true performance.
I tracked key metrics for each method:
- Average return during training
- Final test return and win rate
- Total training time
- And how well each learned policy matched the basic strategy chart
Results
Learning Curve
One of the first things I looked at was the learning curve for each method. This shows the average return during training as episodes progress. You can clearly see how stable or noisy each approach is. For example, On-Policy Monte Carlo and Q-Learning stayed fairly steady and kept improving over time, while the off-policy methods with importance sampling had much higher variance. This highlights how the way you gather and use data can really affect what you see during training.
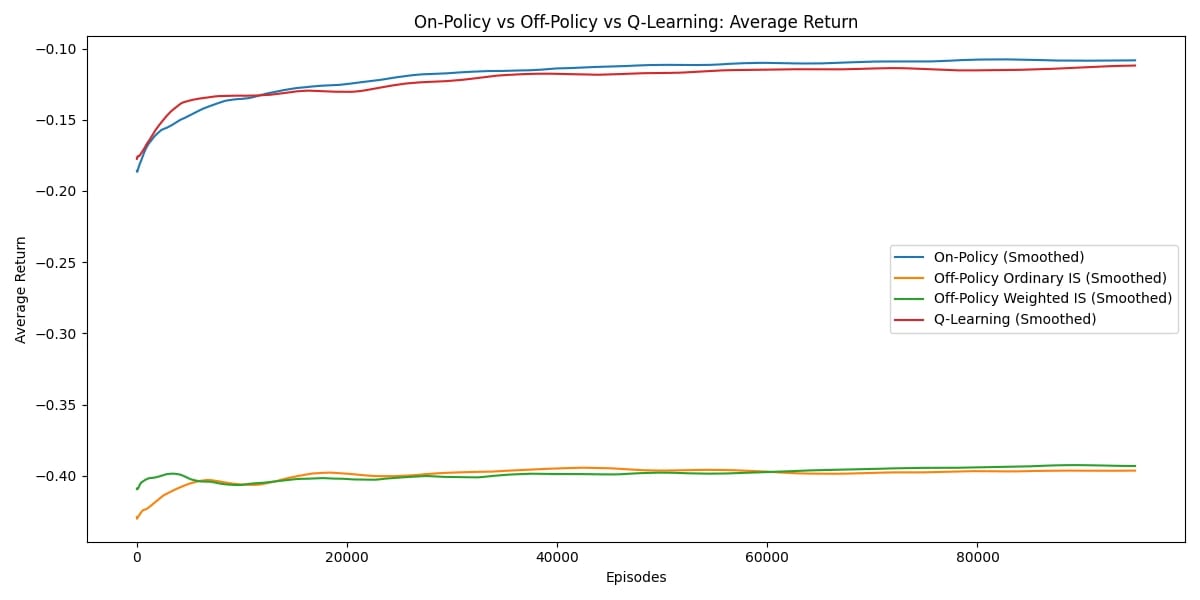
Learning curves for all four methods
Policies Heatmaps
To visualize how each method learned to play, I created heatmaps showing the learned policy for each state. The heatmaps use colors to represent the action probabilities for each possible action (hit or stick) in each state. This gives a clear picture of how the agent behaves in different situations.
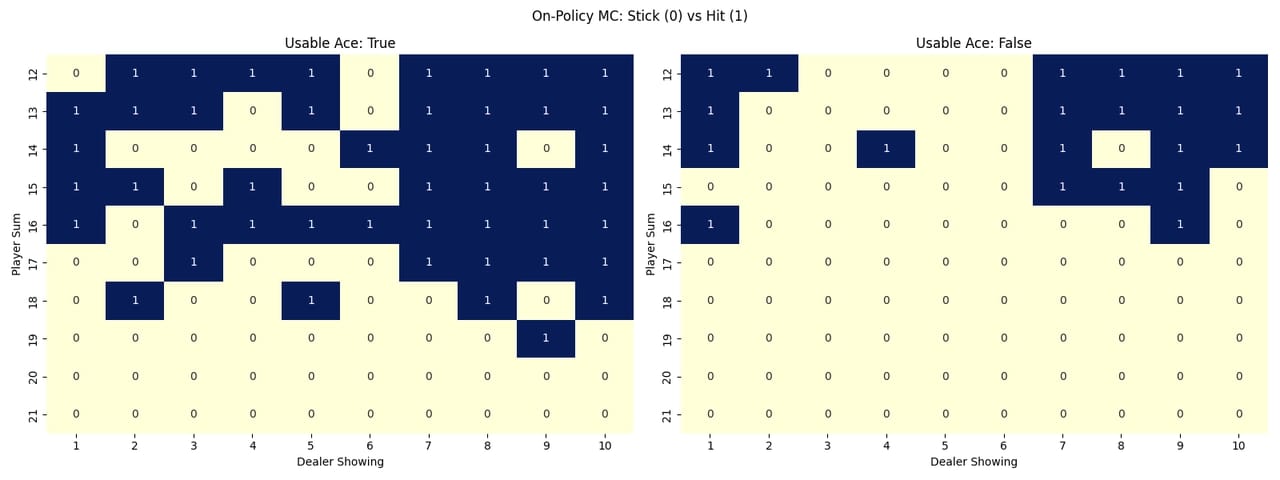
On-Policy Monte Carlo
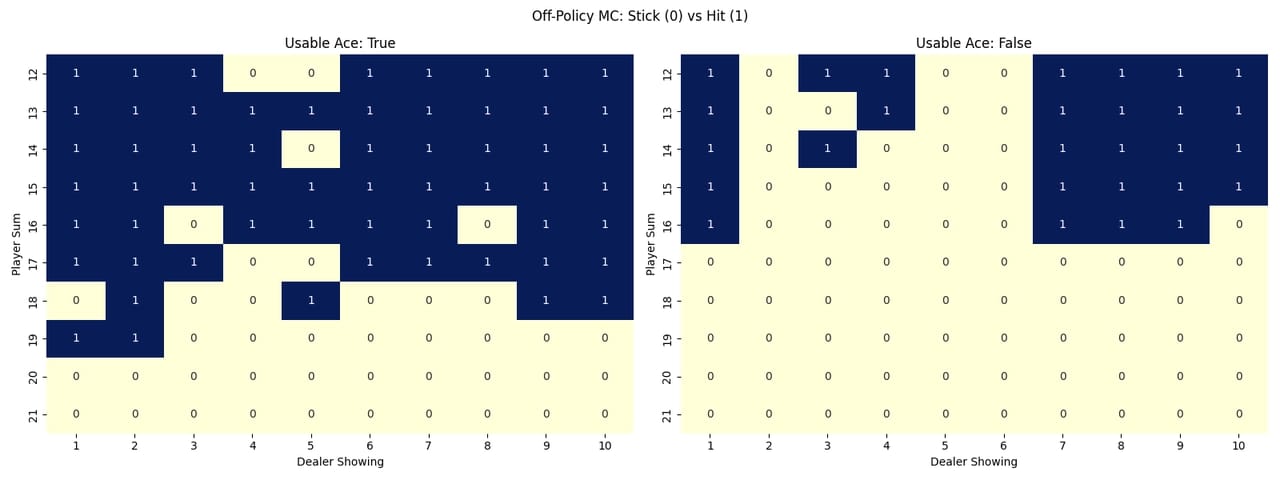
Off-Policy Importance Sampling
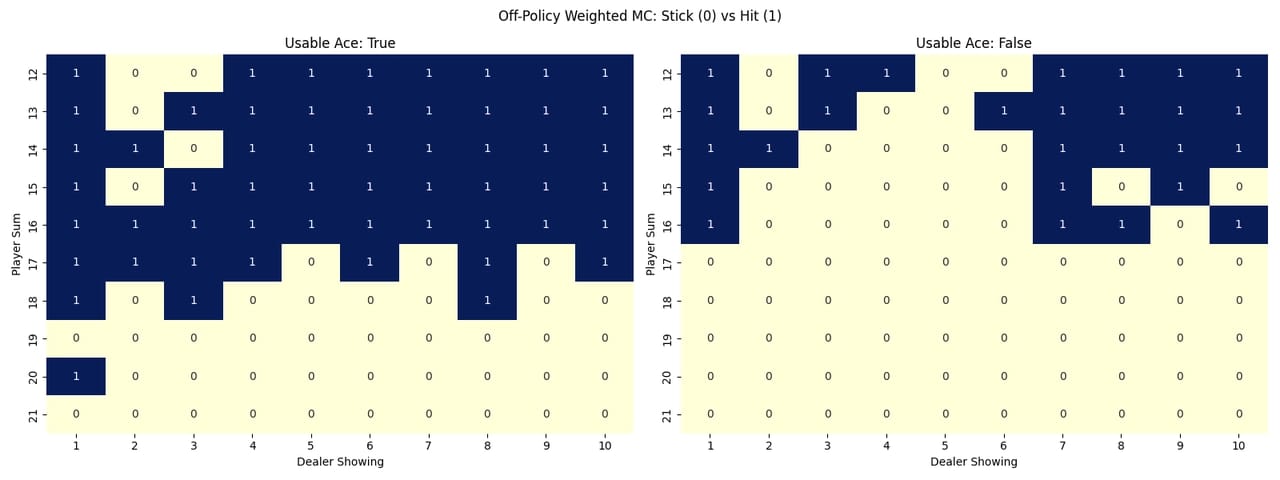
Off-Policy Weighted Importance Sampling
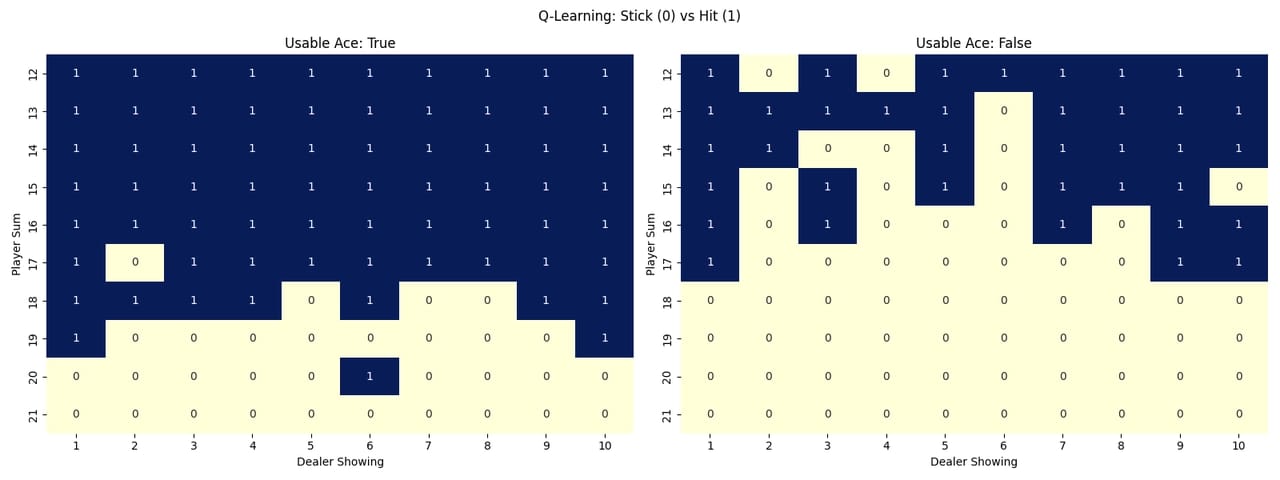
Q-Learning
Comparing to Basic Strategy
To see how well each method learned to play Blackjack, I compared the learned policies to the classic basic strategy. The basic strategy is a well-known optimal way to play Blackjack that minimizes the house edge. I created heatmaps showing both the learned policy and the basic strategy side by side for each method.
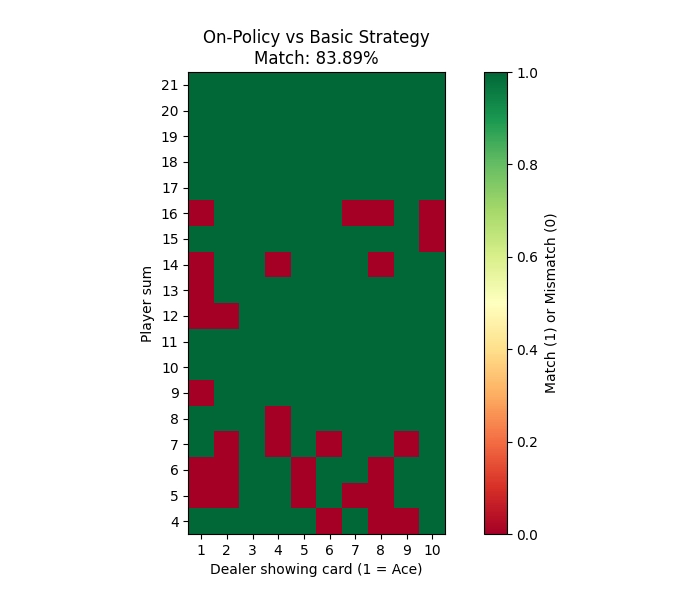
On-Policy Monte Carlo
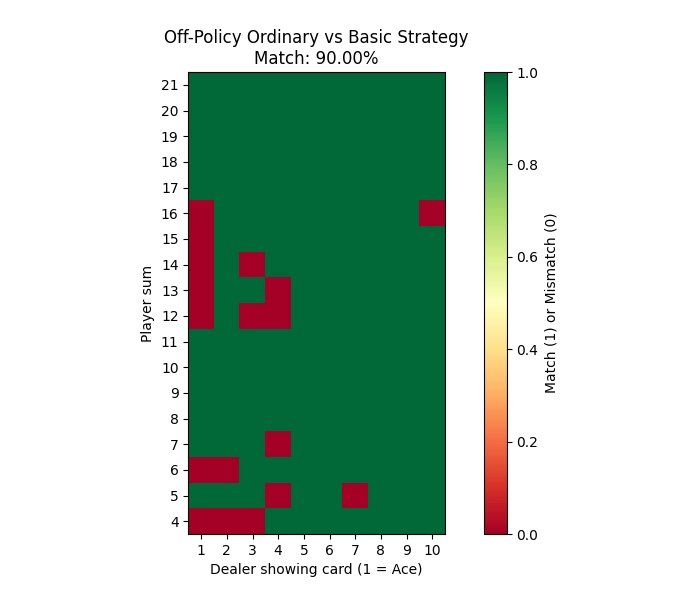
Off-Policy Ordinary Importance Sampling
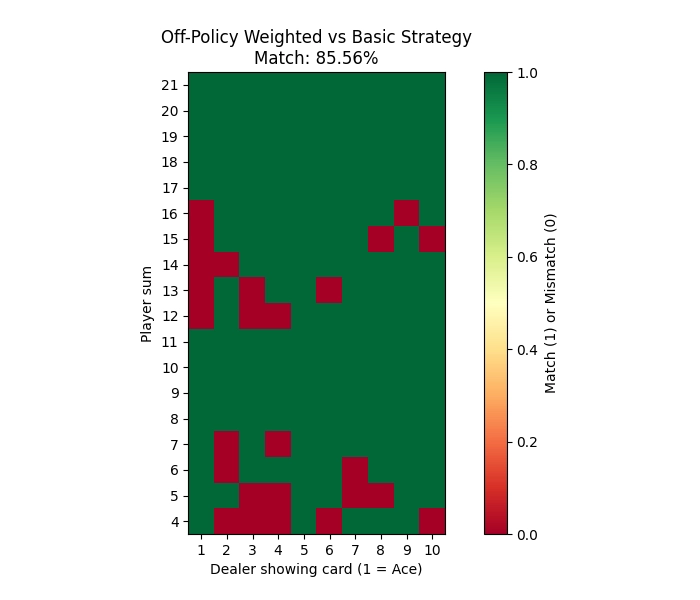
Off-Policy Weighted Importance Sampling
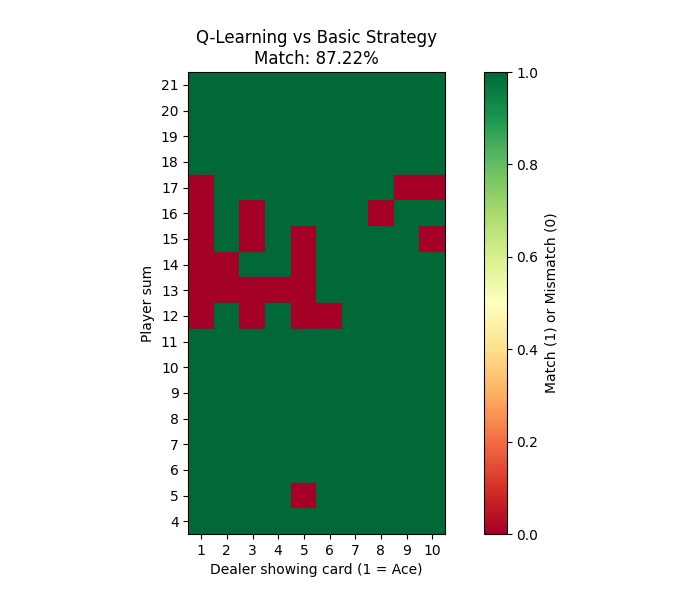
Q-Learning
Final Numbers
Here’s a quick side-by-side comparison of all the key results for each method:
| Method | Train Avg Return | Test Avg Return | Win Rate | Training Time (s) | % Match w/ Basic |
|---|---|---|---|---|---|
| On-Policy MC | –0.1076 | –0.0674 | 42.60% | 123.84 | 83.89% |
| Off-Policy Ordinary IS | –0.3963 | –0.0478 | 43.25% | 123.55 | 90.00% |
| Off-Policy Weighted IS | –0.3931 | –0.0384 | 43.59% | 131.17 | 85.56% |
| Q-Learning | –0.1117 | –0.0665 | 42.18% | 134.38 | 87.22% |
It’s really interesting to see that while the off-policy methods can look rough during training due to high variance, they can still match the basic strategy pretty well if you give them enough episodes. Meanwhile, simpler on-policy MC and Q-Learning stay stable, efficient, and practical for this small game.
Final Thoughts
This little side project really helped me connect what I’m learning in my Reinforcement Learning class with something practical and visual. Seeing how Monte Carlo methods, importance sampling, and Q-Learning behave on a classic problem like Blackjack made the concepts stick so much better.
It was also a good reminder that even when training looks noisy, the final learned policy can still be pretty good, and comparing it to the basic strategy is a great way to see that in action.
If you’re curious, you’re welcome to check out the full code, results, and all the heatmaps in my repo. Feel free to clone it, tweak the number of episodes, test different hyperparameters, or add new methods like SARSA or Double Q-Learning. Contributions or new ideas are always welcome!
Previous Article
LLM Bias in HealthcareNext Article
My First Marathon